K8S调度器研究
总结
关于kube-scheduler的资源记账:
以为的记账流程:
- 研究kube-scheduler代码, 关于nodeInfo里资源的记账, 总是有个误解, 以为会分为三个部分:
- node上全量资源(totalCpu, totalMem)
- node上已经确定占用的资源(usedCpu, usedMem)
- 调度完成, node上待绑定的资源(assumedCpu, assumedMem), 实际绑定成功/失败未知, 只是for调度使用:
- 当绑定成功, 会收到事件, 将assumedCpu/Mem清理, 并把assumedCpu/Mem 放到usedCpu/usedMem里
- 当绑定失败, 会收到事件, 将assumedCpu/Mem清理, 不叠加到usedCpu/usedMem里.
实际的记账流程参照文章 Node allocatable资源的含义
- 但实际上kube-scheduler, 把nodeInfo分为2部分:
- node上全量资源(NodeInfo.Allocatable), 注意之前经常会搞混, 以为allocatable = total - used; 实际上allocatable代表total. 实际发现其他同学也有理解错的: Allocatable Resources is calculated wrong
- node上已经占用的资源(NodeInfo.Requested), 包括如下2部分:
- node上已经确定占用的资源
- 调度完成, node上待绑定的资源(assumedCpu, assumedMem)
- 实际的对账过程:
- 当调度成功, bind前, 会直接把pod.request叠加到node.requested里.
- bind成功, (修改pod状态), node.requested不变
- bind失败, 1秒一次的轮询, 更新pod状态, 将pod的资源归还回node.requested里
- kube-scheduler重启: 会
引发的问题
- kube-scheduler重启, 会执行一次fullsync, cache同步更新量会很大, 耗时可能会比较久, 这中间scheduler是不提供服务的
- 如果多个scheduler同时工作, 由于不共享requestedResource, 并发场景下, 导致资源超卖:
![]()
- 当前解决方案:

如何改进/使用多个scheduler
HOSS方案:
Part1: Job dispatch:
- instanceLevel load balancing: 防止某些scheduler非常繁忙, 某些scheduler非常空闲.
- dynamic scheduling policy: 基于scheduler的标签, 进行调度

方案总结: 即新增scheduler-controller模块, 对多个scheduler进行进一步调度
Part2: Conflict resolution:
![]()
方案总结: 即在api-server增加conflict-resolver模块, 识别binding的request, 进行冲突校验, 进行failfast.
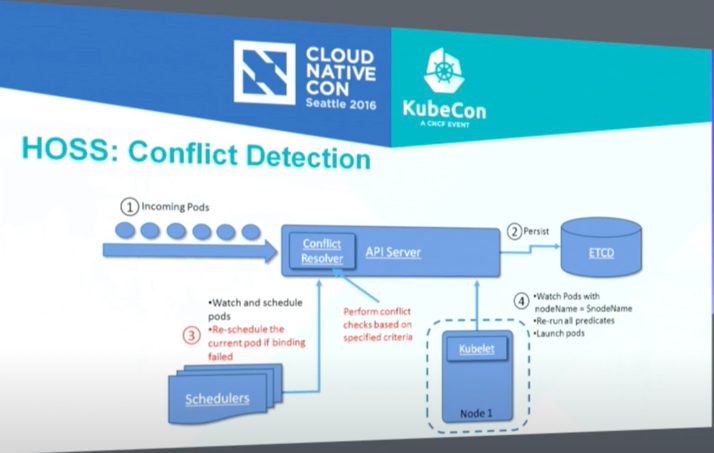
HOSS与kube-scheduler的对比

关于k8s中大页内存资源管理
限制条件:
- Nodes must pre-allocate huge pages in order for the node to report its huge page capacity.
- A node can only pre-allocate huge pages for a single size.
- Unlike CPU or memory, huge pages do not support over-commitment. (普通k8s的memory是如何over-commit的?)
如何在node上开启&分配大页内存(并上报到apiserver?)
- k8s中, node上需要实现定义&分配好大页内存, 如下, 注意下边
bootloader部分: - 同时要注意, 可以在node运行时分配大页内存, 也可以在node boot时分配. 但最好在boot时分配, 因为运行时可能由于内存碎片, 无法分配出对应数量的大页内存.
- 如下例子, 分配2M的大页内存, 数量是50个
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: hugepages
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Boot time configuration for hugepages
include=openshift-node
[bootloader]
cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=50
name: openshift-node-hugepages
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-hp"
priority: 30
profile: openshift-node-hugepages如何在pod创建时声明使用大页内存?
k8s中, pod使用是通过volumes来进行大页内存的Requests, 如下(下边的是单个node支持多种大小的大页内存, 但实际一般一个node只会支持一种大页内存大小):
apiVersion: v1
kind: Pod
metadata:
name: huge-pages-example
spec:
containers:
- name: example
image: fedora:latest
command:
- sleep
- inf
volumeMounts:
- mountPath: /hugepages-2Mi
name: hugepage-2mi
- mountPath: /hugepages-1Gi
name: hugepage-1gi
resources:
limits:
hugepages-2Mi: 100Mi
hugepages-1Gi: 2Gi
memory: 100Mi
requests:
memory: 100Mi
volumes:
- name: hugepage-2mi
emptyDir:
medium: HugePages-2Mi
- name: hugepage-1gi
emptyDir:
medium: HugePages-1Gi