十万个为什么--用晶体管数量衡量芯片的先进性合理么?
0x00: Intro
最近在看 The Basic Principles of Computers for Everyone 这本书, 从
- 与非门(NAND) 开始, 加上非门, 构建与门
- 4个NAND构建一位带开关的存储单元(M);
- 8个存储单元(M)构建1Byte的存储(B)
- 8个与门构建一个8位的Enabler(E)
- B+E 构建一个 8位 寄存器(R) + 总线
- 8个与门+3个非门构建一个 3X8译码器(Decoder)
- 1个8位寄存器&2个4X16译码器(用于寻址) + 256个1位寄存器(R)&3个与门(用于存数) 构建 256位 的RAM
等等, 非常深入浅出. 后边会把读书笔记补充上来.
忍不住思维跳跃了下, 构建一个256位的RAM至少需要((4*8+8) + (4+16) + (4+1)*256 + 3 = 1343)个门(4个MOS管构建出一个与非门, 但当前主流的都是FinFET, 场效应晶体管). 虽然是RAM的实现, 与实际CPU上L1/L2/L3Cache的实现方式不同, 但也能基本说明点儿问题, 就是我们构建CPU/DRAM等都需要庞大数量的晶体管.
想起苹果2021发布的M1 Max芯片, 晶体管数量是570亿, 57 billion transistors, 例如自己在用的Intel Xeon E5 2660 V3, 也有2.6 billion个transistors. 这种庞大的数字, 总是让人很震撼. 也无外乎厂商会用这个数字来吹嘘, 来作为重要指标, 说明自己的CPU/芯片有多复杂多先进. 毕竟芯片面积总共就那么大, 10倍晶体管数量的提升, 基本就只能提升密度了, 也就是得靠先进制程等.
但我们技术人都要有批判性思维, 仔细再想下, CPU中几乎一半的面积都是L3 Cache, Cache的电路设计并不复杂, 因此都是先进制程带来的红利么? 晶体管数量庞大, 真的能说明技术NB么?
遂搜索了下资料, 发现果然有人砸场子的, Transistor Count: A Flawed Metric, 在标题里就明确之处, 晶体管数量是一个有缺陷的指标. 详细阅读了之后, 我试着总结下作者的几个理由.
0x01: 晶体管数量是数不准的!!
厂商给出的晶体管数量都是一个近似值. 同样的设计, 晶体管数量会有33%到37%的误差. 为啥呢? 摘录 为什么说Intel的10nm工艺比别家7nm更先进? 中的片段:
比较古老的一种计量密度的方法,其实是用 CPP(contacted poly pitch,即 gate pitch,栅间距)去乘以 metal pitch 最小金属间距。
到了 FinFET 晶体管时期,增加 fin(鳍)高度、减少 fin 之间的间距就能有效增加驱动电流。驱动电流上去之后,就可以减少 fin 的数量——一个单元减少 fin 的数量,也就实现了金属 track 的减少,可以降低动态功耗,与此同时确保性能,甚至还能通过一些优化手法来提升速度。
在金属 track 减少之后,传统计算密度的方法其实就不怎么准确了,因为它其实不能反映单元高度减少这样的实际结构变化。所以后来有方法是 CPP 乘以 MMP(最小金属间距),再乘以 Track 数。
但更多的结构优化,比如后文会提到的 COAG 技术进一步降低了单元高度,同时采用 dummy gate 来缩减单元的宽度。那么在单元宽度、高度同时降低的情况下,上面这种计算方法就又不准确了。
所以如今的晶体管数字,更多的应当作为一种参考来看,毕竟晶体管并不是以均匀的方式分布在 die 上的。
0x02: 不同类型的芯片, 设计目标是有差异的, 不会一味追求高密度
例如
- ASCI芯片, 只需要达到目标的吞吐量即可, 不需要追求高主频. 例如
Cisco Silicon One, 只需要达到目标的400Gbps以太网吞吐量即可. 因此ASCI设计团队更倾向于 1. 使用自动化设计工具 2. 更少的定制电路 3. 更高密度晶体管(单Fin的FinFET晶体管). - 服务器芯片追求更高频率, 例如
Xeon 8268和Xeon 8260都有24 Core, 但8268的频率是2.9GHz, 8260是2.4GHz, 价格相差了$1600. 因此服务器芯片设计更倾向于 1. 更多的定制电路 2. 更大的晶体管(2Fin, 3Fin甚至更多Fin的FinFET晶体管)TODO: FinFET中Fin数量与主频的关系是?
0x03. 芯片中不同功能区域密度不同
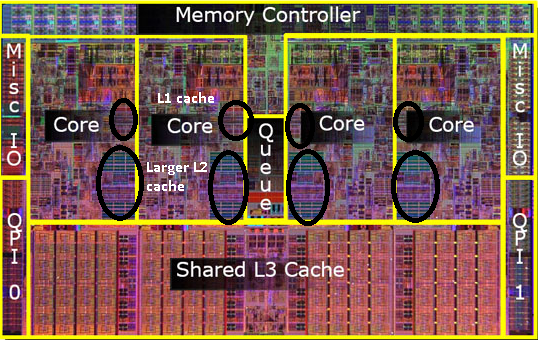
如上图, 处理器组成部分:
- CPU Cores, 包含 cores, L1 Cache, L2 Cache
- L3 Cache
- System Interface
- I/O, 包含 QPI, DIMM
如下两个处理器, 都是for服务器场景:
如上图, CPU 不同区域, 密度差异能高达20倍. 例如Poulson的L3 Cache密度是13.33Mtr/mm2, 但IO区域密度是0.65Mtr/mm2
Naturally, the cache region which primarily comprises ultra-dense SRAM is the densest and makes up most of the transistors in each design.
The I/O is the least dense portion of the two designs, because it contains many delicate analog circuits such as PLLs and DLLs, digital filters, and the large, high-voltage I/O transistors that are used to transmit and receive off-chip data.
如果只追求高密度, 庞大数量, 直接堆L3Cache就行了.
0x04: 实际有很多无效的晶体管
正常工作的叫做active transistors, 但实际上, 生产出来的芯片里还会包含:
- dummy transistors: 主要用来提升良品率, 但数量不算那么庞大.
- decap transistors(decoupling capacitors): 数量就比较巨大了.
To ensure yield, the die must be relatively uniform and the whitespace cannot be truly empty. Many designs will fill the whitespace with decap cells to provide decoupling capacitance for power delivery and thereby improve operating frequency.
实际上无效晶体管数量占到了20%~30%, 甚至更多.
They found that in the small sampled regions that the active transistors were between 70-80% of the total, and the remaining 20-30% of layout transistors were decap and dummy devices.
0x05. 晶体管不贵多而贵在精
例如 AMD Radeon VII 比 RX 5700多了28%的transistors, 但是两者性能差不多. 部分原因是RX 5700使用了更加先进的架构, 而且RX 5700要便宜很多.
When it comes to actual value to customers, it’s not about the transistor count, but how the transistors are used.
0x06: 总结
所以, 这东西就跟娱乐大师跑分一样, 只作为一个参考项, 不要作为唯一指标. 不能一叶障目不见泰山.
更重要的是, 我们技术人, 需要保持独立思考能力, 知其然, 也要知其所以然, 不要被厂商忽悠了.
0xFF:其他一些好玩儿的科普
- L3 Cache为啥不能做得更大一些? 直接替换掉RAM不行么?