K8s PodDisruptionBudget 详解
k8s-pdb
自愿中断&非自愿中断
非自愿中断
- 物理机硬件故障
- 云厂商故障导致节点消失 —> Spot中断目前应该属于这个的一部分.
- 由于NodePressure导致的Pod驱逐 (注意, 这个属于非自愿中断)
自愿中断
由应用管理员或者集群管理员出发的.
- 删除deploy/其他controller, 下边管控了pod
- 修改deploy
- 直接delete pod
- drain Node
哪些行为会考虑PDB?
- 非自愿中断, 都不会考虑PDB
- 自愿中断中, 部分行为会考虑PDB
Not all voluntary disruptions are constrained by Pod Disruption Budgets.
For example, deleting deployments or pods bypasses Pod Disruption Budgets.
- 只针对如下4个会考虑PDB
Deployment
ReplicationController
ReplicaSet
StatefulSet实际样例
创建PDB/Deployment
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: myapp-pdb
spec:
minAvailable: 4
selector:
matchLabels:
app: myapp
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
spec:
replicas: 5
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: nginx手动delete pod → 不受PDB限制
手动删除pod 不受pdb限制.
但可以安装这个kubectl的增强,https://github.com/ueokande/kubectl-evict 从而可以evict pod, 用来测试PDB
手动drain node —> 受PDB限制
drain node的时候:
- 首先会把node设置为 SchedulingDisabled 状态
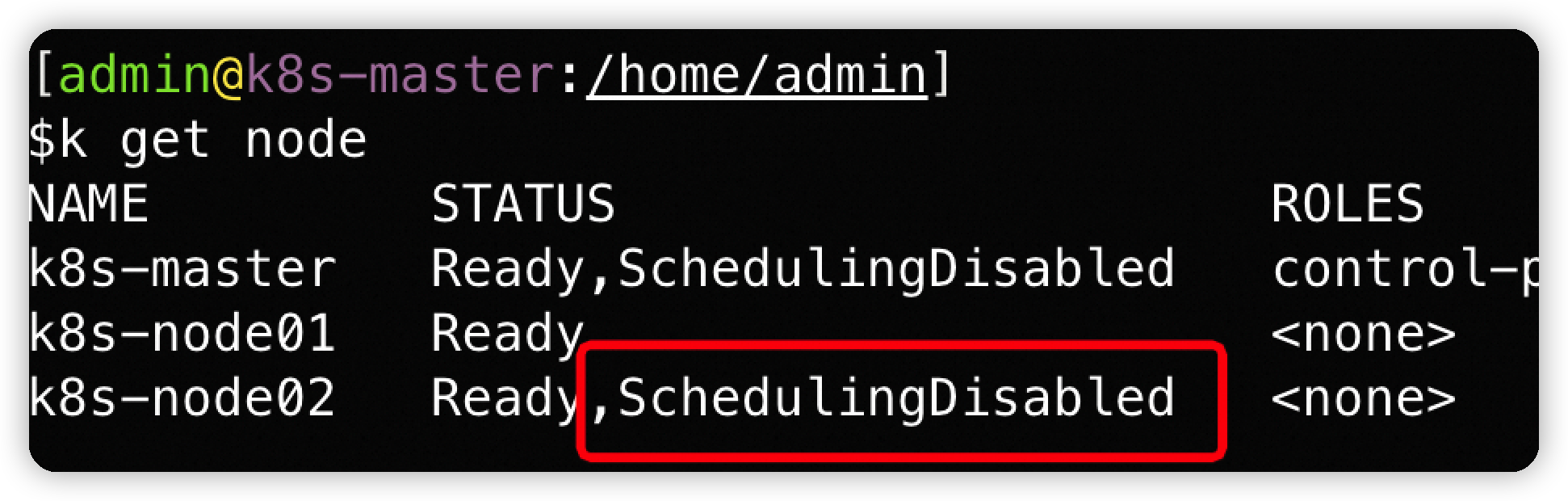
- 然后会检查PDB
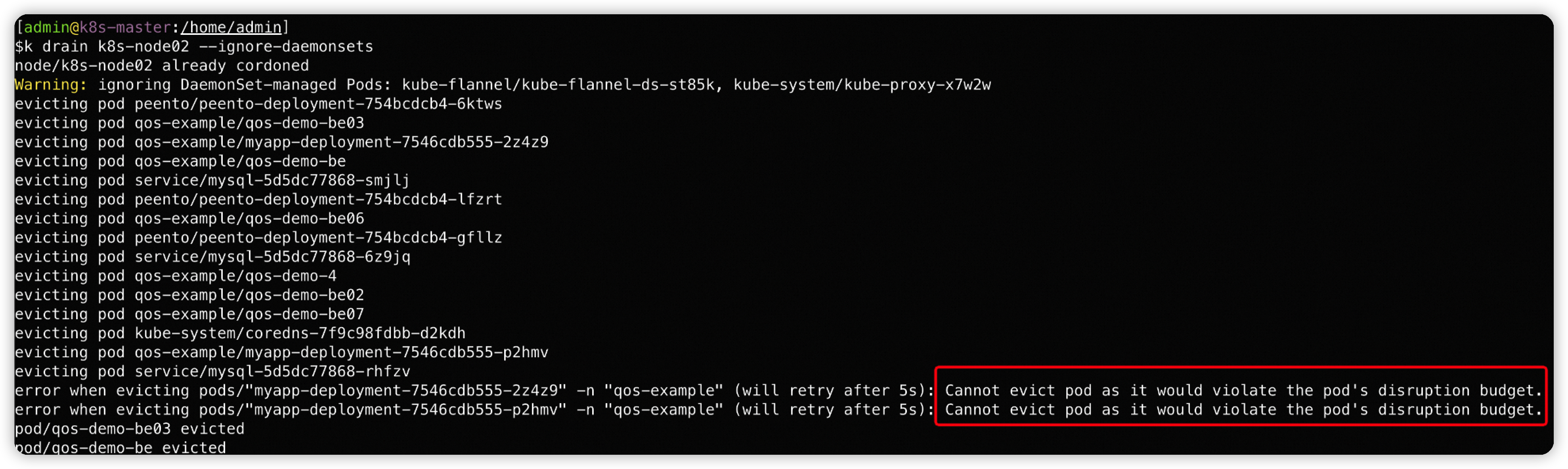
手动缩容deploy → 不受PDB限制
会导致pdb处于unhealthy状态:
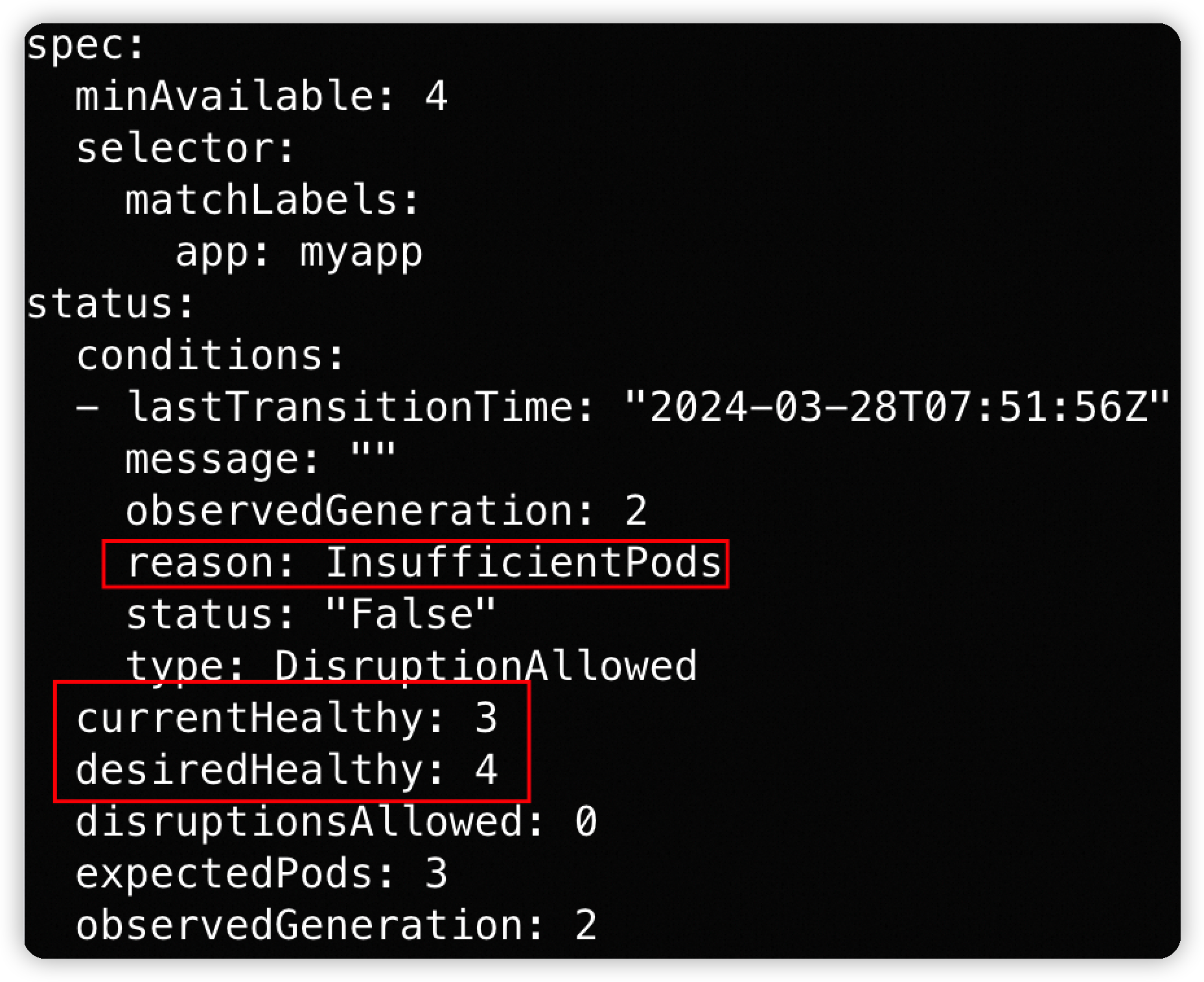
手动扩容deploy → 不受PDB限制
- 当扩容 deploy之后 ,状态就正常了
总结
- 本质上需要区分2个角色:
- 应用管理员
- 集群管理员
- 而PDB实际就是 集群管理员 与 应用管理员 的一个沟通界面. 假设集群管理员要drain一个node, 但如果没有PDB, 根本无法阻止集群管理员的drain. 从而导致应用受损.
FAQ:
maxUnavailablecan only be used to control the eviction of pods that have an associated controller managing them.- 也就是说给单个pod指定了
maxUnavailable=0, 同时drain node, 测试, 实际pod是会忽略掉这个pdb约束的 - pod必须属于某个
- 也就是说给单个pod指定了
