K8s CPU Manager 与 Cgroups v1
k8s-cpumanager-cgroupsv1
主要来分析对cgroups的操作与设计逻辑, 底层driver使用的是sysd
- CgroupsPerQOS 是干嘛用的?
- 默认开启. 开启之后, 会在
/sys/fs/cgroup/cpuset/kubepods.slice下新建kubepods-burstable.slicekubepods-besteffort.slice两个cgroup组, 后续pod都会放到对应的cgroup组里. 而 GU的pod则直接在/sys/fs/cgroup/cpuset/kubepods.slice下新建cgroup.
systemctl status kubepods.slice
/run/systemd/system/kubepods.slice
**systemctl status system.slice
/usr/lib/systemd/system/system.slice交互方式
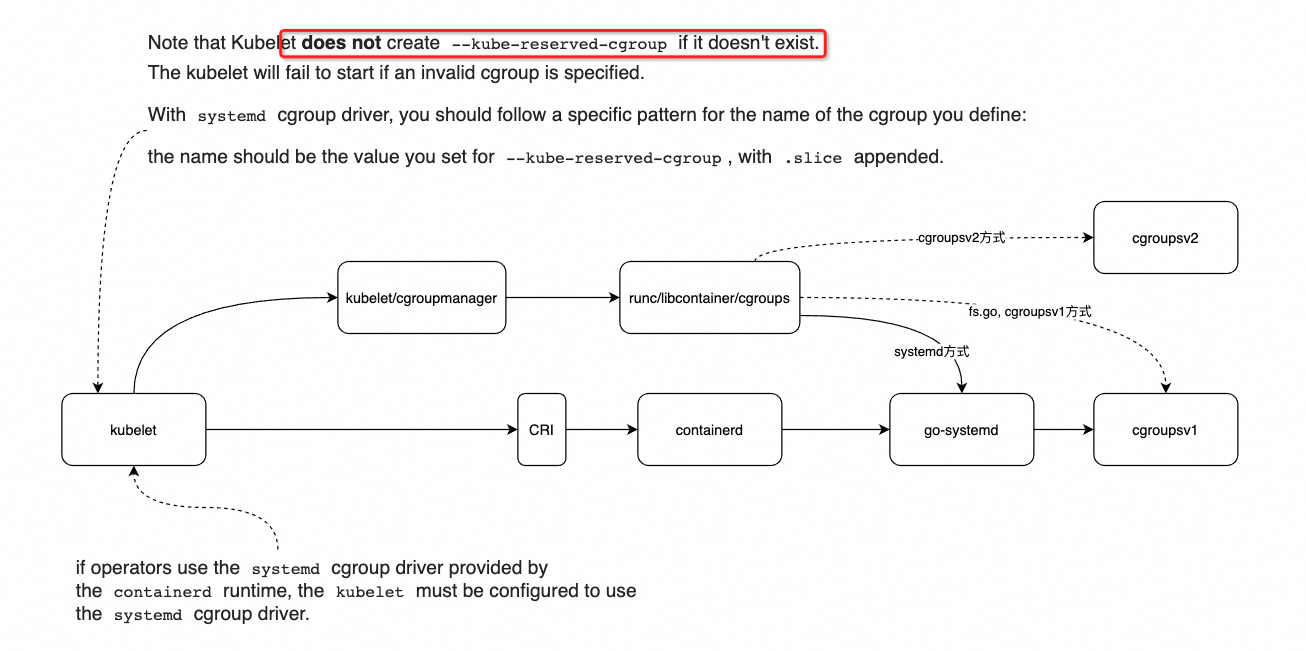
底层如何与cgroups交互?
核心就是使用 go-systemd 库, 依赖关系如下:
带着疑问出发
- kubelet啥时候为kube-reserved, system-reserved 新建的cgroups?
- 目前看起来, kubelet不会为这两个新建cgroups.
- 而是需要运维人员提前在node上
- 啥时候把kubelet的进程放到了cgroups里?
- 怎么知道其他的系统进程有哪些? 如何把sysreserved正常配置上去?
- kubereserved 与 sysreserved 是如何分配的?
- 只指定了cpuset预留, 那么 kubelet 与 sys 会都绑定这些cpuset么?
/var/lib/kubelet/cpu_manager_state文件是啥时候写入的?- cgroups内容是啥?
交互流程
- 创建kubelet:
在 NewContainerManager 里, 使用如下关键信息, 把 KubeReserved + SystemReserved 分配的cpuset放到 kubeDeps#ContainerManager#cpuManager#policy#reservedCPUs 字段
kubeDeps#ContainerManager#NodeConfig#NodeAllocatableConfig#KubeReserved
kubeDeps#ContainerManager#NodeConfig#NodeAllocatableConfig#SystemReserved
kubeDeps#ContainerManager#NodeConfig#NodeAllocatableConfig#ReservedSystemCPUs —> 用户静态分配的cpuset
- 启动kubelet:
预留底层实现
预留样例
- Node Capacity为 16C64Gi
- 以如下参数为例: (注意没有设定
SystemReservedCgroupKubeReservedCgroup这两个参数)
# /var/lib/kubelet/config.yaml
cpuManagerPolicy: "static"
kubeReserved:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "1Gi"
systemReserved:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "1Gi"
$sudo cat /var/lib/kubelet/cpu_manager_state
{"policyName":"static","defaultCpuSet":"0,4-8,12-15","entries":{"088fe178-cec9-4eb9-ba3c-cf45cba46371":{"qos-demo-ctr":"1,9"},"681eca58-a216-4ec4-a57b-941cad3c4e0f":{"qos-demo-ctr":"2-3,10-11"}},"checksum":2993692383}
$sudo cat /var/lib/kubelet/memory_manager_state
{"policyName":"None","machineState":{},"checksum":4236770233}- 在 k8s 中看到的Node资源情况, 如下, Allocatable.cpu = 14 了
Capacity:
cpu: 16
ephemeral-storage: 51343996Ki
hugepages-1Gi: 4Gi
hugepages-2Mi: 6444Mi
memory: 65435804Ki
pods: 110
Allocatable:
cpu: 14
ephemeral-storage: 45171142988
hugepages-1Gi: 4Gi
hugepages-2Mi: 6444Mi
memory: 52443292Ki
pods: 110kubelet预留cgroup结构 —> 完全没有限制
- kubelet CPU限制: kubelet本身进程会放在
/sys/fs/cgroup/cpu/system.slice/kubelet.service目录下, 行为是: 不会进行绑核, 可以所有核随便飘, 但在争抢激烈时, 只能使用1C的资源
# 如下, systemd里并没有任何限制 (这点与后边实际Pod的有所区别)
[admin@k8s-node01:/usr/lib/systemd/system]
$cat kubelet.service
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=https://kubernetes.io/docs/
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/bin/kubelet
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target
# 如下, 只在 cgroups 里进行了限制 --> 但尝试了下, 发现即使没有定义kube-reserved等参数, 默认值仍然也会是1024
[admin@k8s-node01:/sys/fs/cgroup/cpu/system.slice/kubelet.service]
$cat cpu.shares
1024
[admin@k8s-node01:/sys/fs/cgroup/cpu/system.slice/kubelet.service]
$cat cpu.cfs_quota_us
-1
[admin@k8s-node01:/sys/fs/cgroup/cpu/system.slice/kubelet.service]
$ps aux | fgrep kubelet
root 77344 0.6 0.1 2409184 104956 ? Ssl Jan17 10:58 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --container-runtime-endpoint=unix:///var/run/containerd/containerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
[admin@k8s-node01:/sys/fs/cgroup/cpu/system.slice/kubelet.service]
$cat cgroup.procs
77344
[admin@k8s-node01:/sys/fs/cgroup/cpu/system.slice/kubelet.service]
$cat tasks
38337
77344
...
# 由于没有绑核, 因此 /sys/fs/cgroup/cpuset 下没有 system.slice 文件夹 --> 但怎么保证不会占用已经分配给pod的 1,9, 2-3, 10-11 这几个CPU呢?
# 通过限制 kubepods.slice 只能使用14个CPU
[admin@k8s-node01:/sys/fs/cgroup/cpu/kubepods.slice]
$cat cpu.shares
14336
[admin@k8s-node01:/sys/fs/cgroup/cpu/kubepods.slice]
$cat cpu.cfs_quota_us
-1
# 通过限制 kubepods.slice 从而保证正常容器只能使用 60Gi 内存
[admin@k8s-node01:/sys/fs/cgroup/memory/kubepods.slice]
$cat memory.limit_in_bytes
64858779648- kubelet MEM限制: 也完全没有进行限制
[admin@k8s-node01:/sys/fs/cgroup/memory/system.slice/kubelet.service]
$cat memory.limit_in_bytes
9223372036854771712system预留cgroup结构 —> 完全没有限制
- system CPU限制:
[admin@k8s-node01:/sys/fs/cgroup/cpu/system.slice]
$cat cpu.shares
1024
[admin@k8s-node01:/sys/fs/cgroup/cpu/system.slice]
$cat cpu.cfs_quota_us
-1
## 如下, system.slice文件夹里包含了一堆子的service, 实际看了下, 这些service的 cpu.shares都=1024, cpu.cfs_quota_us=-1
[admin@k8s-node01:/sys/fs/cgroup/cpu/system.slice]
$l -d */
drwxr-xr-x 2 root root 0 Jan 16 19:34 system-teamd.slice/
drwxr-xr-x 2 root root 0 Jan 16 19:34 syslog-ng.service/
drwxr-xr-x 2 root root 0 Jan 16 19:34 containerd.service/
...
drwxr-xr-x 2 root root 0 Jan 16 19:34 system-getty.slice/
drwxr-xr-x 2 root root 0 Jan 18 15:03 kubelet.service/
# 实际在systemd文件目录下查看, 发现这些子的service也都没有配置CPU/MEM的限制, 样例如下:
[admin@k8s-node01:/usr/lib/systemd/system]
$cat containerd.service
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target
[Service]
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/bin/containerd
Type=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=infinity
# Comment TasksMax if your systemd version does not supports it.
# Only systemd 226 and above support this version.
TasksMax=infinity
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target- system MEM限制: —> 与kubelet的mem类似, 在cgroups里也没有进行mem的限制
[admin@k8s-node01:/sys/fs/cgroup/memory/system.slice]
$cat memory.limit_in_bytes
9223372036854771712
[admin@k8s-node01:/sys/fs/cgroup/memory/system.slice/containerd.service]
$cat memory.limit_in_bytes
9223372036854771712为啥完全没有限制呢?
设置
kubeReserved只是 kubelet 用来计算节点可用资源的一种方式,并不一定会在操作系统层面严格限制资源使用。
要实现严格限制,你需要结合使用--kube-reserved-cgroup参数和相应的 cgroup 配置。
Note that Kubelet does not create –kube-reserved-cgroup if it doesn’t exist.
The kubelet will fail to start if an invalid cgroup is specified.
With systemd cgroup driver, you should follow a specific pattern for the name of the cgroup you define:
the name should be the value you set for –kube-reserved-cgroup, with .slice appended.
这也就解释了, 为啥没有配置 --kube-reserved-cgroup 参数的时候, 行为是上边的样子, 即没有实际在node的cgroups上限定cpu/mem的用量, 只是在记账层面(即上报给scheduler的allocatable)进行了资源的预扣减.
但为啥不帮忙创建一个呢?
—reserved-cpus
注意, 这个选项设定之后, k8s只能保证 kubepods.slice 下 GU 的pod不会使用这些cpu, 但无法保证:
- 要真正让kubelet这些组件运行在reserved-cpus上, 需要自己额外来搞, kubelet不会帮忙搞.
- BE/Burstable 的 pod 也有可能运行在
--reserved-cpus上
To move the system daemon, kubernetes daemons and interrupts/timers to the explicit cpuset defined by this option,
other mechanism outside Kubernetes should be used.
For example: in Centos, you can do this using the tuned toolset.
TODO: 但实际试了下, 设定了cgroups, 貌似也没用. 待后续研究!!!
CPU/MEM Pod实现✅
pod的整体比较清晰.
4C2Gi的Pod, 通过containerd→systemd:
GU Pod实现
- 4C2Gi的GU Pod
# systemd配置
[admin@k8s-node01:/run/systemd/system/cri-containerd-9dddbeeec375157f294b1bdc9278be2d2a07e0ace1fa9a0e39b8008a1d440722.scope.d]
$cat 50-CPUShares.conf
[Scope]
CPUShares=4096
[admin@k8s-node01:/run/systemd/system/cri-containerd-9dddbeeec375157f294b1bdc9278be2d2a07e0ace1fa9a0e39b8008a1d440722.scope.d]
$cat 50-CPUQuota.conf
[Scope]
CPUQuota=400%
[admin@k8s-node01:/run/systemd/system/cri-containerd-9dddbeeec375157f294b1bdc9278be2d2a07e0ace1fa9a0e39b8008a1d440722.scope.d]
$cat 50-MemoryLimit.conf
[Scope]
MemoryLimit=2097152000
## 疑问: 为啥在systemd的.conf文件里, 没有cpuset相关的信息? 但实际cpuset又确实是有值的?
# cgroups实际
## cpuset:
[admin@k8s-node01:/sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod681eca58_a216_4ec4_a57b_941cad3c4e0f.slice/cri-containerd-9dddbeeec375157f294b1bdc9278be2d2a07e0ace1fa9a0e39b8008a1d440722.scope]
$cat cpuset.cpus
2-3,10-11
## cpu.cfs_quota_us cpu.shares
[admin@k8s-node01:/sys/fs/cgroup/cpu/kubepods.slice/kubepods-pod681eca58_a216_4ec4_a57b_941cad3c4e0f.slice/cri-containerd-9dddbeeec375157f294b1bdc9278be2d2a07e0ace1fa9a0e39b8008a1d440722.scope]
$cat cpu.cfs_quota_us
400000
[admin@k8s-node01:/sys/fs/cgroup/cpu/kubepods.slice/kubepods-pod681eca58_a216_4ec4_a57b_941cad3c4e0f.slice/cri-containerd-9dddbeeec375157f294b1bdc9278be2d2a07e0ace1fa9a0e39b8008a1d440722.scope]
$cat cpu.shares
4096
## mem --> mem 限制是生效的
[admin@k8s-node01:/sys/fs/cgroup/memory/kubepods.slice/kubepods-pod681eca58_a216_4ec4_a57b_941cad3c4e0f.slice/cri-containerd-9dddbeeec375157f294b1bdc9278be2d2a07e0ace1fa9a0e39b8008a1d440722.scope]
$cat memory.limit_in_bytes
2097152000BE Pod实现
# 新创建一个BE的Pod
##### cpu.shares 行为
## 父目录里的 cpu.shares 为最小值2
[admin@k8s-node01:/sys/fs/cgroup/cpu/kubepods.slice/kubepods-besteffort.slice]
$cat cpu.shares
2
## pod目录下 cpu.shares 也为最小值2
[admin@k8s-node01:/sys/fs/cgroup/cpu/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod0d2b11f5_eeb4_47b2_a5a1_5199e549890b.slice]
$cat cpu.shares
2
## container目录下, cpu.shares 也为最小值2
[admin@k8s-node01:/sys/fs/cgroup/cpu/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod0d2b11f5_eeb4_47b2_a5a1_5199e549890b.slice/cri-containerd-e70683ab49ee18bb677cfb2429838ad0860365df844fcf4f99bba805c6bb2da1.scope]
$cat cpu.shares
2
##### cpuset 行为
## 观察cpuset如下: parent里不识别哪些CPU已经被GU占用了
[admin@k8s-node01:/sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice]
$cat cpuset.cpus
0-15
## pod目录下, 也不识别哪些CPU已经被GU占用了
[admin@k8s-node01:/sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod0d2b11f5_eeb4_47b2_a5a1_5199e549890b.slice]
$cat cpuset.cpus
0-15
## 只在各个子的实际的container里才会识别到哪些CPU被占用了
[admin@k8s-node01:/sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod0d2b11f5_eeb4_47b2_a5a1_5199e549890b.slice/cri-containerd-e70683ab49ee18bb677cfb2429838ad0860365df844fcf4f99bba805c6bb2da1.scope]
$cat cpuset.cpus
0,4-8,12-15Burstable Pod实现

k8s系统组件
通过kube-admin搭建的集群, 发现 node上的
- kube-flannel-ds-st85k
- core-dns
默认是burstable的; cgroups限制统一放在 /sys/fs/cgroup/cpu/kubepods.slice/kubepods-burstable.slice 下
而
- kube-proxy
默认是 best-effort 的. cgroups限制统一放在 /sys/fs/cgroup/cpu/kubepods.slice/kubepods-besteffort.slice 下
k8s下cgroups的结构层次
Node上视角:
- 查看kubelet的cgroups操作driver: systemd/cgroupsv1/cgroupsv2
$sudo vim /var/lib/kubelet/config.yaml
cgroupDriver: systemd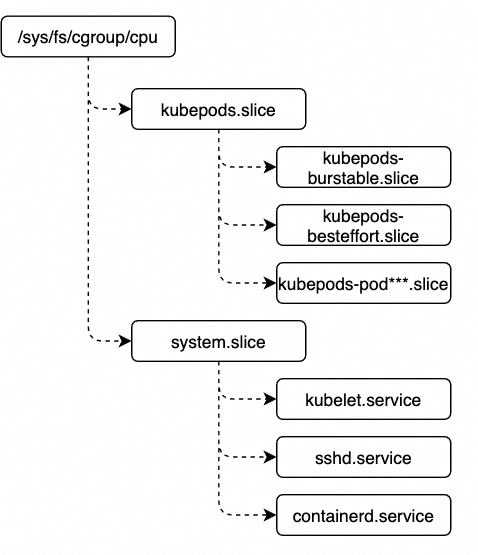
Pod里视角:
Pod会限制每个Container的cpu/mem:
