k8s cpu manager deep dive
k8s-cpu-manager-deep-dive
系统组件预留
几种预留方案
–reserved-cpus=0-3 : 代表把CPU0~CPU3预留给系统组件/k8s组件;
–kube-reserved
—kube-reserved-cgroup
–system-reserved
–system-reserved-cgroup
–reserved-cpus —> 这种cgroups是谁来创建 并把kubelet放入到这个cgroups里的?
资源逻辑
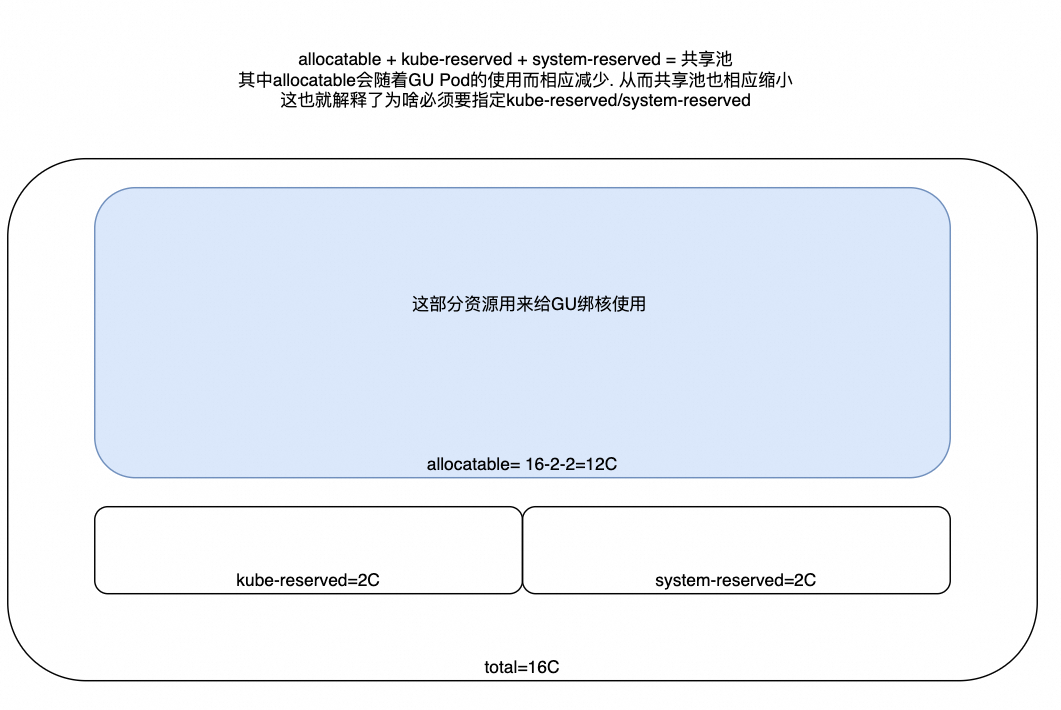
- 这也就解释了为啥一旦开启 static 策略, 要求必须要有 kube-reserved/system-reserved 设定. 因为假设没有设置, 那么allocatable的就是整台物理机, 也就是存在GU Pod把CPU全给绑定完导致CPU耗尽,
- 一是导致系统组件等没有CPU可以使用; —> 勘误, 此处实际系统组件是可以使用allocatable的cpu的.
- 二是导致BE/Burstable的Pod也无法调度到该Node上(即官方文档中的 因为零预留 CPU 值可能使得共享池变空。
如何指定预留参数启用kubelet
# 第一步: 修改kubelet的配置文件
$ sudo vim /var/lib/kubelet/config.yaml
cpuManagerPolicy: "static"
kubeReserved:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "1Gi"
systemReserved:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "1Gi"
# 第二步: 查看当前缓存文件, 并删除
$sudo cat /var/lib/kubelet/cpu_manager_state
## 当前使用的是none
{"policyName":"none","defaultCpuSet":"","checksum":1353318690}
$sudo rm -f /var/lib/kubelet/cpu_manager_state
# 第三步: 重启kubelet&查看服务状态&是否启用成功
$sudo systemctl daemon-reload
$sudo systemctl restart kubelet
$sudo systemctl status kubelet
$sudo journalctl -u kubelet
Jan 17 09:43:00 k8s-node01 kubelet[77344]: I0117 09:43:00.988280 77344 cpu_manager.go:214] "Starting CPU manager" policy="static"
# 第四步: 查看新的绑核状态
$sudo cat /var/lib/kubelet/cpu_manager_state
{"policyName":"static","defaultCpuSet":"0,4-8,12-15","entries":{"088fe178-cec9-4eb9-ba3c-cf45cba46371":{"qos-demo-ctr":"1,9"},"681eca58-a216-4ec4-a57b-941cad3c4e0f":{"qos-demo-ctr":"2-3,10-11"}},"checksum":2993692383}
# 第五步: 在k8s中查看node状态, 如下 Capacity代表整机能力, 而Allocatable=Capacity-KubeReserved-SystemReserved; 即使Node上已经被新建的Pod占用了6个Core, 但这里Allocatable却始终保持不变.
$kubectl describe node k8s-node01
Capacity:
cpu: 16
ephemeral-storage: 51343996Ki
hugepages-1Gi: 4Gi
hugepages-2Mi: 6444Mi
memory: 65435804Ki
pods: 110
Allocatable:
cpu: 14
ephemeral-storage: 45171142988
hugepages-1Gi: 4Gi
hugepages-2Mi: 6444Mi
memory: 52443292Ki
pods: 110实现逻辑分析
以 v1.22.0 版本为例分析:
如何判断pod的QoS?
由于cpu-manager只针对 GU 的 QoS 会绑核, 因此判断 Pod 的 QoS 至关重要.
核心逻辑是:
pkg/apis/core/v1/helper/qos/qos.go:39
原则如下:
- 所有的container都没有指定request&limit, → BE
- 所有的container都指定了request&limit, 且 request == limit, → GU
- 其他的组合都是 Burstable, 例如
- 指定了request, 没指定limit
- 指定了limit, 没指定request
- 部分container的request=limit, 部分container不相同
绑核
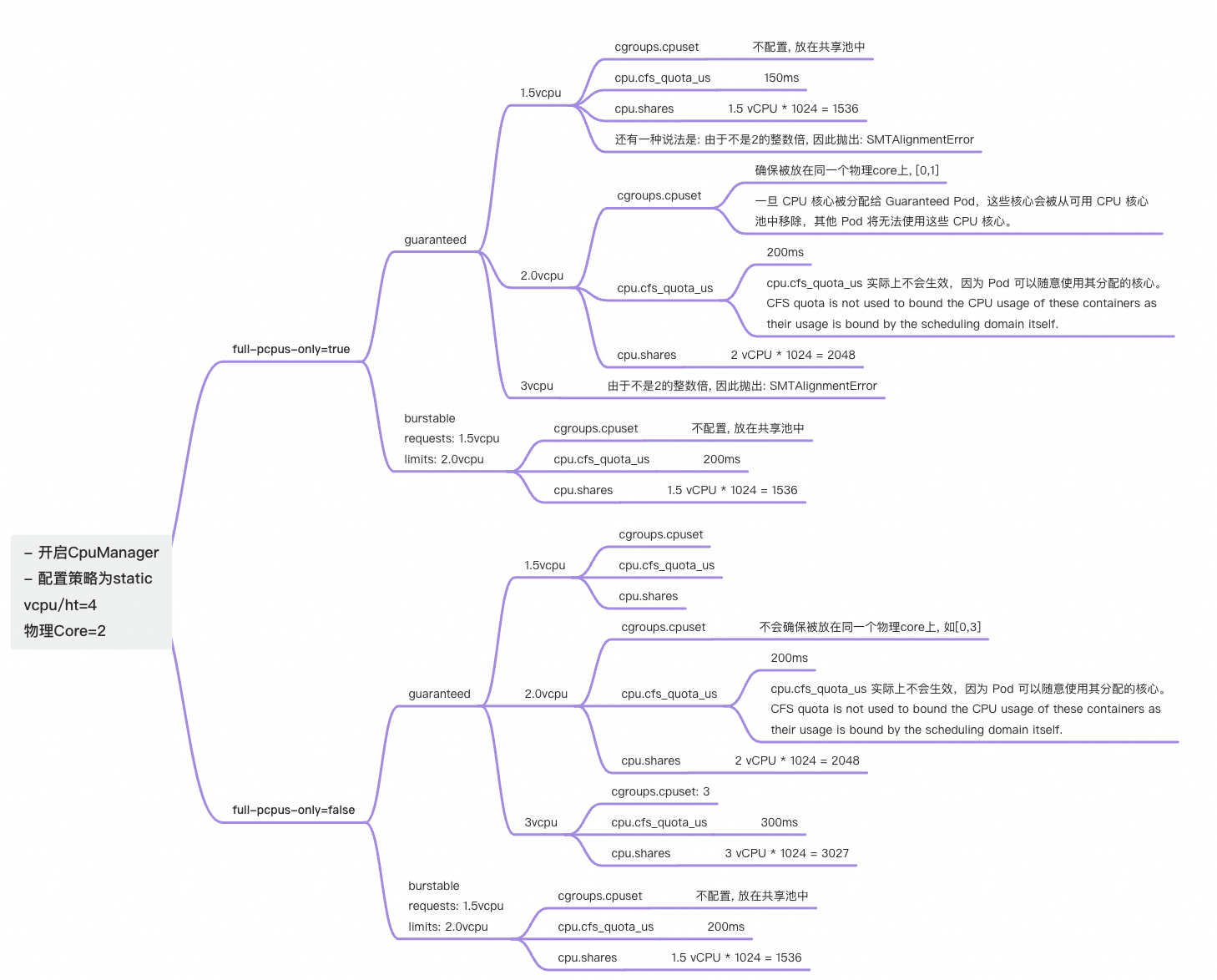
- 开启cpu manager, 且使用Static policy; 则针对 CPU请求为整数的
Guaranteed pod, 会进行绑核
Only containers that are both part of a Guaranteed pod and have integer CPU requests are assigned exclusive CPUs.
- 调度逻辑: 独享的pod占用的core就从整体可用的cpu里扣掉. 但区别是
- k8s是放在内存里, 周期性巡检. 通过CR方式上报到apiserver
- 具体实现:
- 通过 cpuset.cpus 来实现绑核
- 绑核的pod不再设置 cfs_quota
- 但还是会设定 cpu.shares
不绑核
- 不开启cpu mananger 或者 非Guaranteed Pod, 则都不绑核, 默认使用:
- cfs_quota_us 来进行限制cpu量, 与 limit 相同, 用于限制最大的绝对量.
- cpu.shares 来进行, 与requests相同, 用于限制在竞争时可用的cpu量. 每个cpu被分为1024个share
重要说明
- 绑核是针对的整个Pod粒度. 而不是container粒度.
- Pod内各个container的request/limit资源, 具体是如何分配的? 是谁来分配的? container的争抢如何处理?
- taskAPI?
整体梳理
pkg/kubelet/cm/cpumanager/cpu_assignment.go:186 takeByTopology
在numa策略为null的场景下, 分配策略为:
- 首先尝试独占整个socket; –> 优先填满
- 其次尝试独占整个物理core; –> 优先填满
- 最后才在剩余的vcpu上进行分配.
例如:
2个Socket, 每个Socket上4个物理Core, 每个物理Core有2个HT; 的空机器
- 1vcpu请求: 走到第三步, (因为无法填满/独占socket/core),
- 6vcpu请求: 走第二步(因为无法填满/独占socket), 只能独占 core1,core2,core3
- 10vcpu请求: 先走第一步, 独占socket0, 满足8vcpu需求; 其次使用第二步, 独占socket1上的一个物理core;
case分析
case1:
如下拓扑结构, 请求了 4C 的GU Pod, (没有配置bindToNuma, 没有配置FullPCPUsOnlyOption) 那么会如何分配&绑核?
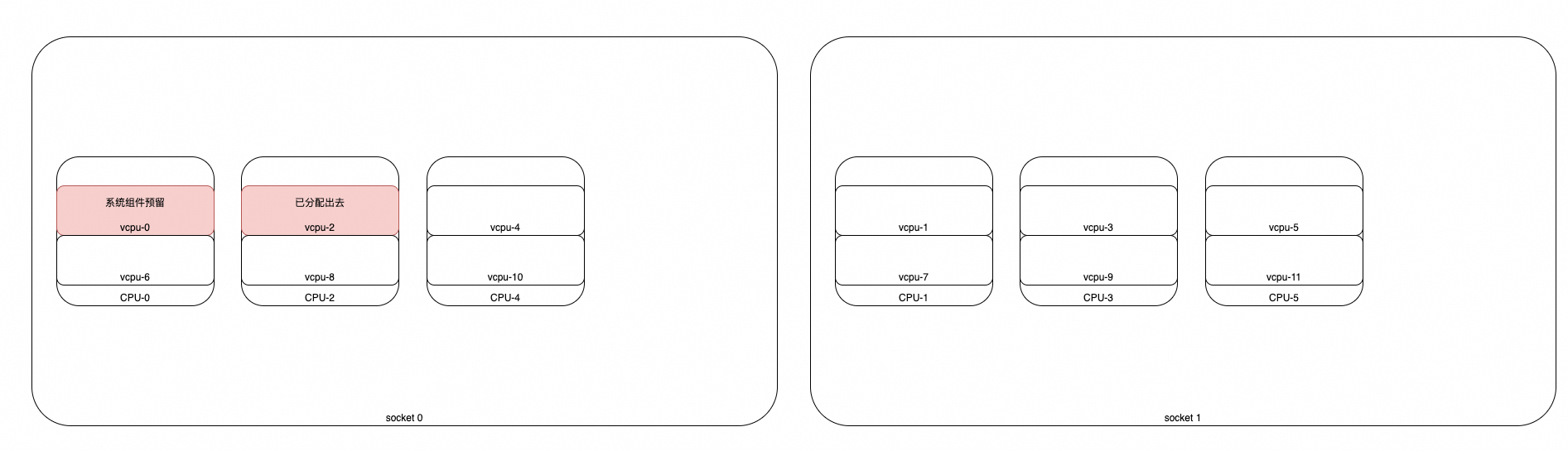
- 可能性1: [1,3,7,9]
- 可能性2: [1,4,7,10] ✅
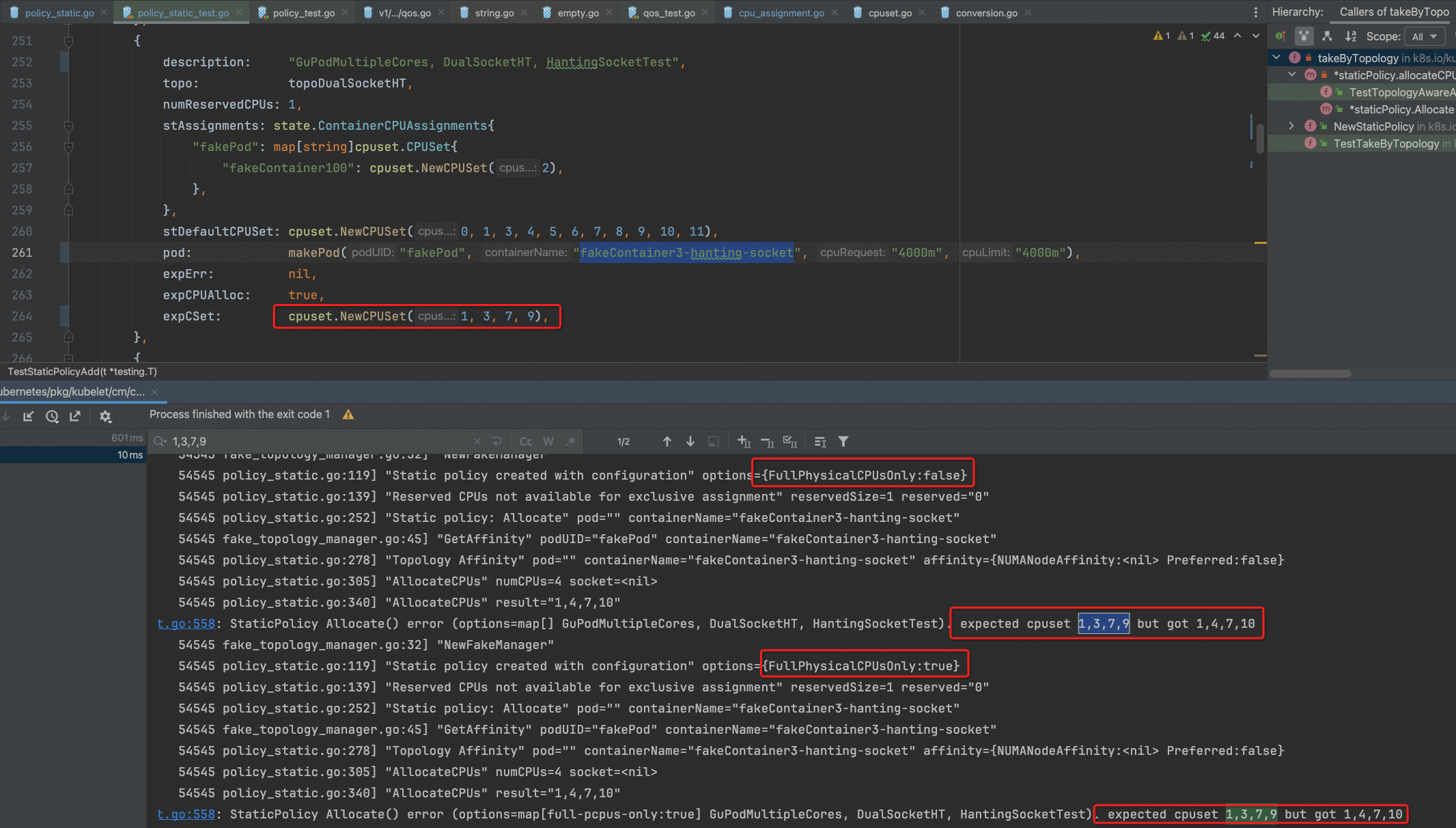
为啥会这样? 本质还是看代码的实现:
pkg/kubelet/cm/cpumanager/cpu_assignment.go:186 takeByTopology
- 尝试去占满整个Socket, 此时Free的只有Socket-1; 但4C的请求占不满, 因此取消.
- 尝试去占满整个pcpu, 此时Free的pcpu有: [pcpu1, pcpu3, pcpu4, pcpu5]; 因此只需要占用2个pcpu即可. 但具体占用哪2个?
- 优先按照socket中剩余可用的vcpu数量进行升序排列, 即剩余vcpu越少的socket, 越优先; 即优先填满一个socket;
- 本例中socket-0可用vcpu为4; socket-1可用vcpu为6;
- 因此优先
- 优先按照socket中剩余可用的vcpu数量进行升序排列, 即剩余vcpu越少的socket, 越优先; 即优先填满一个socket;
这个分配方式是有优化空间的,
case2:
如下拓扑结构, 请求了 4C 的GU Pod, (没有配置bindToNuma, 没有配置FullPCPUsOnlyOption) 那么会如何分配&绑核?
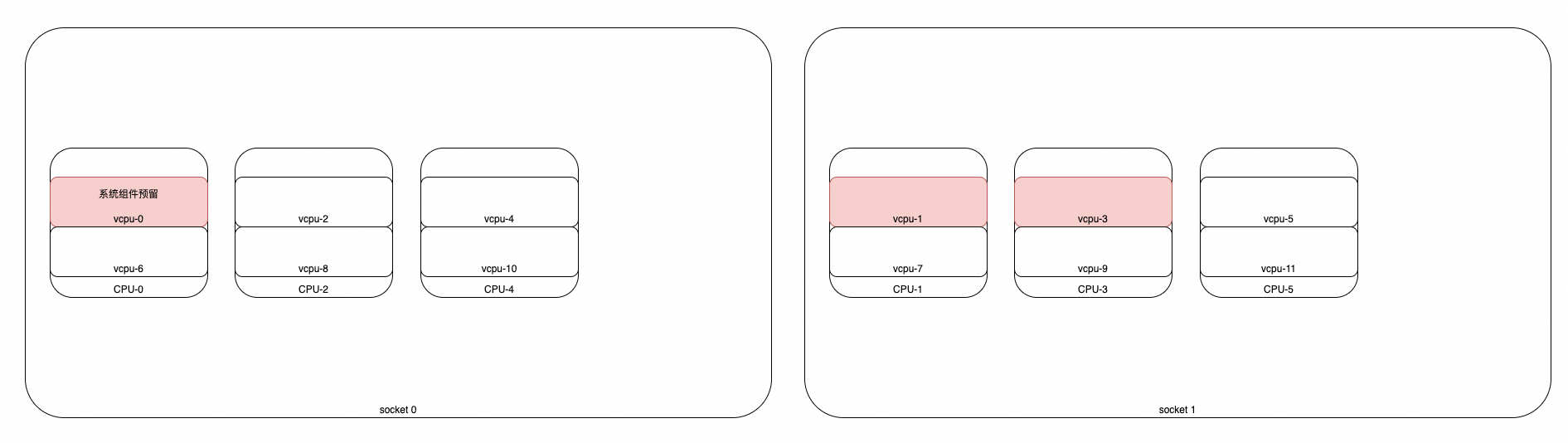
- 可能性1: [2,4,8,10]
- 可能性2: [2,5,8,11] ✅
按照case1的逻辑来推演下即可. —> 按照Socket剩余的free的vcpu来选择socket
case3
如下拓扑结构, 请求了 4C 的GU Pod, (没有配置bindToNuma, 没有配置FullPCPUsOnlyOption) 那么会如何分配&绑核?
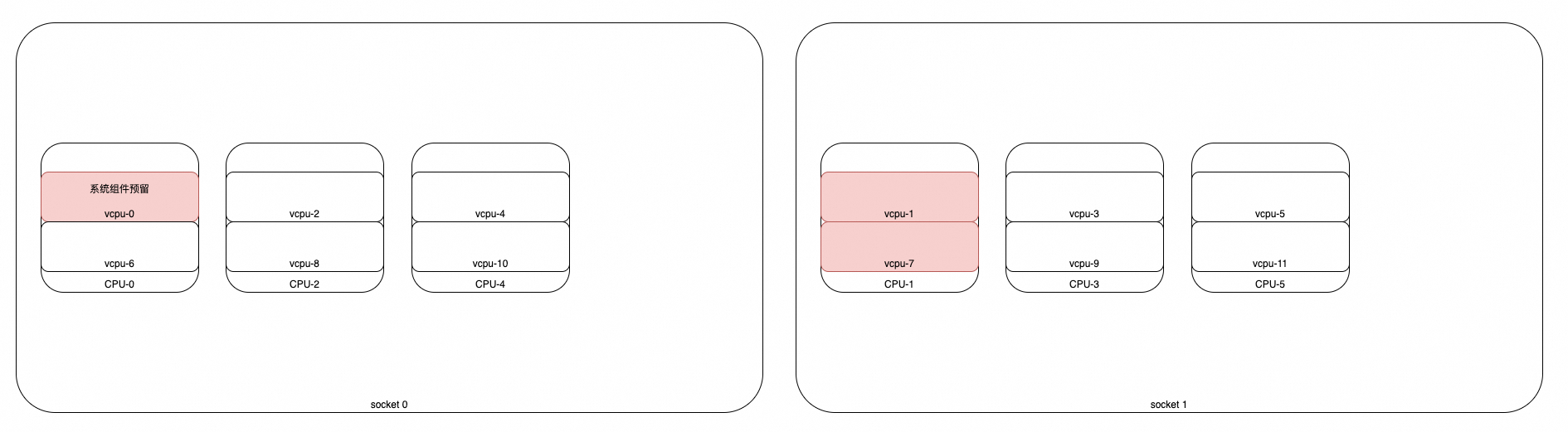
- 很容易得出结论: [3,5,9,11]
case4
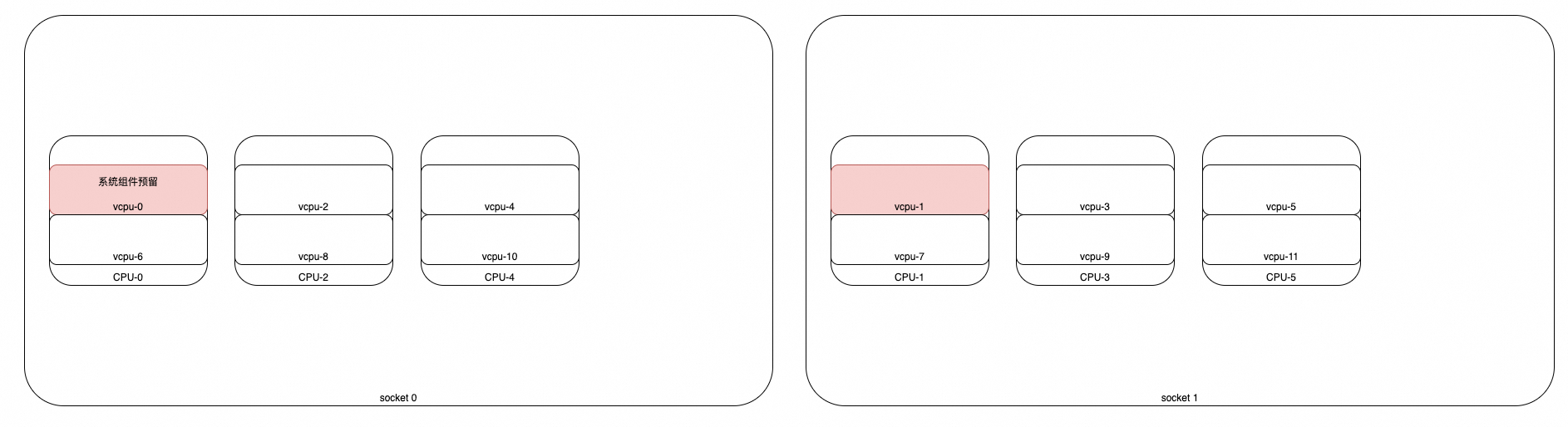
- 结论: [2,4,8,10] ✅
case分析: reserved机制
- 系统组件预留是怎么work的?
case分析: full-pcpus-only
1.22版本: 为啥感觉 full-pcpus-only 实现有点儿问题呢? 即使 full-pcpus-only=true, 也有可能跨pcpu
1.29版本:
case分析: distribute-cpus-across-numa
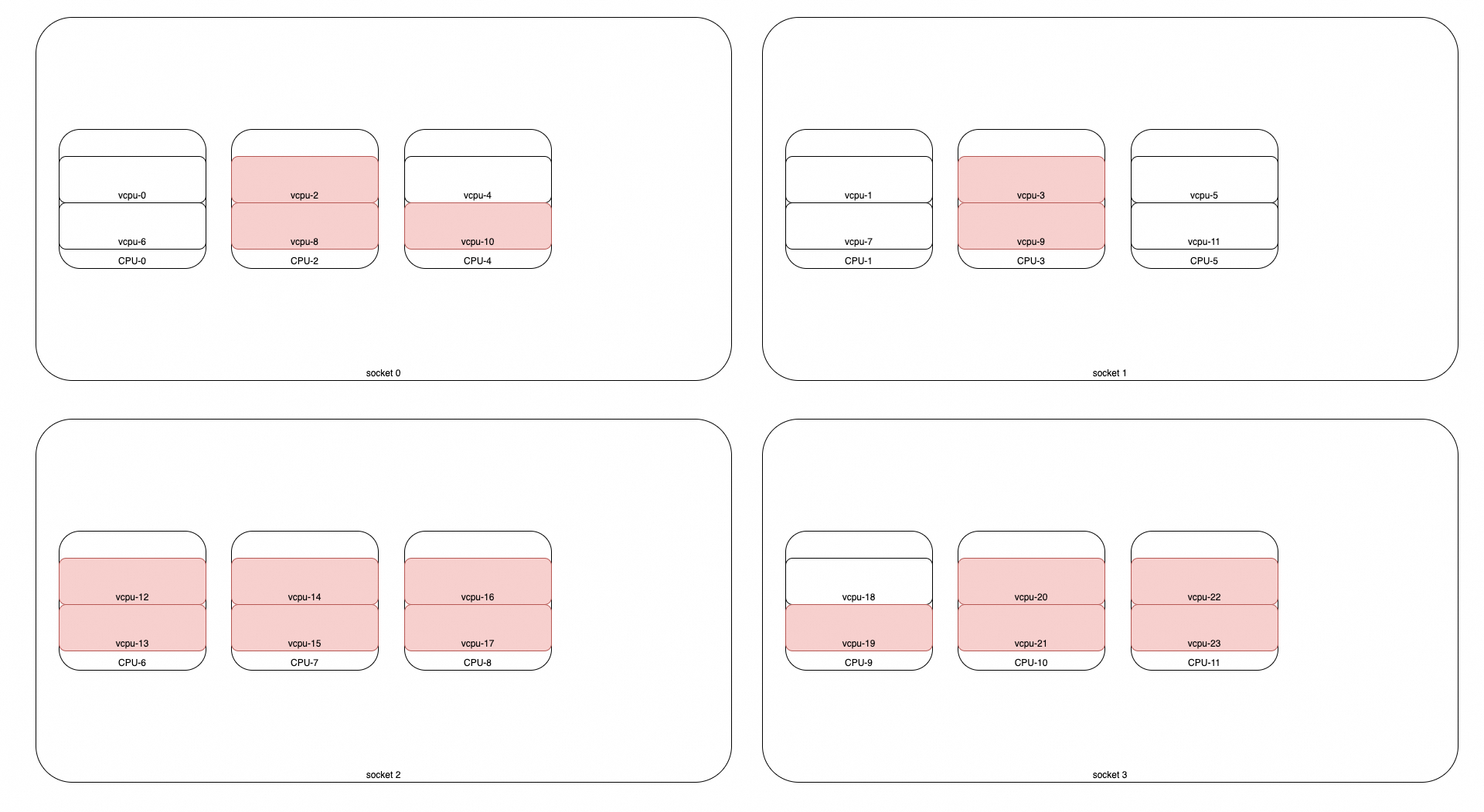
逻辑概览:
- 如果请求能被单个numa满足, 则在单个numa里堆叠分配;
- 如果无法被1个numa满足, 则尝试在2个numa里平均分配; 每个numa内部堆叠分配;
- …
- 如果都不行, 则降级到堆叠分配
例如:
- 请求2个vcpu: numa0[0, 6]
- 请求3个vcpu: numa0[0, 4, 6]
- 请求4个vcpu: numa0[0, 6] numa1[1, 7]
- 请求5个vcpu: numa0[0, 6, 4] nuam1[1, 7] —> 降级到普通堆叠调度
- 请求6个vcpu:
case分析: align-by-socket
AlignBySocket —> 即socket聚合
AlignBySocket 选项 与 TopologyManager的 PolicySingleNumaNode 是不兼容的. —> 为啥不兼容?
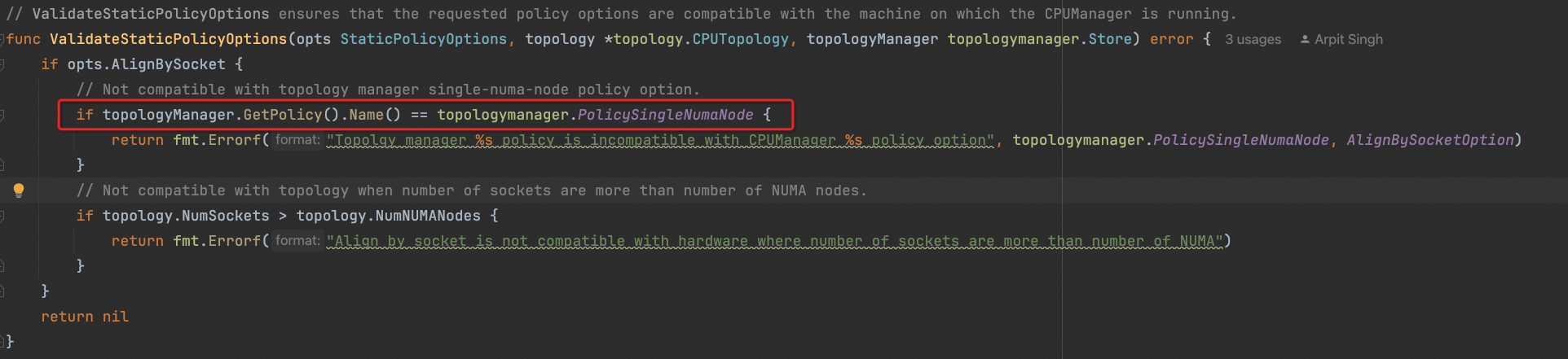
术语一直不统一, 但至少在cpumanager里
- core: 代表pcpu
- cpu: 代表vcpu
针对没有开numa的机器, 能否也使用绑核机制?
Refs
- k8s官方文档: Control CPU Management Policies on the Node | Kubernetes
- K8s 节点 CPU 升级,导致 kubelet 无法启动故障一例
- Kubernetes 陈年老 bug - 绑核