K8s 故障排查指南
k8s-troubleshooting
Disk Pressure
错误现象
“Disk usage on image filesystem is over the high threshold, trying to free bytes down to the low threshold”

如何排查?
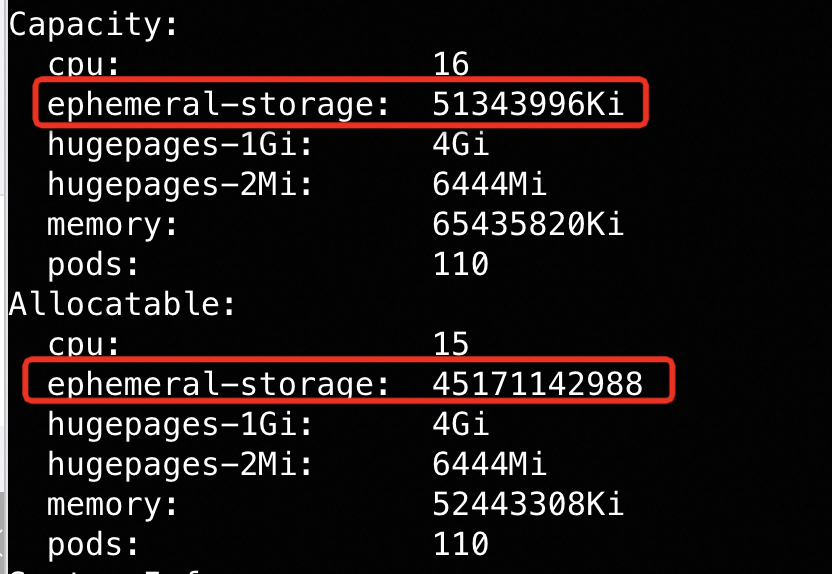
第一步: k describe node
如下,
- capacity 是:
- allocatable 是:
- allocated:
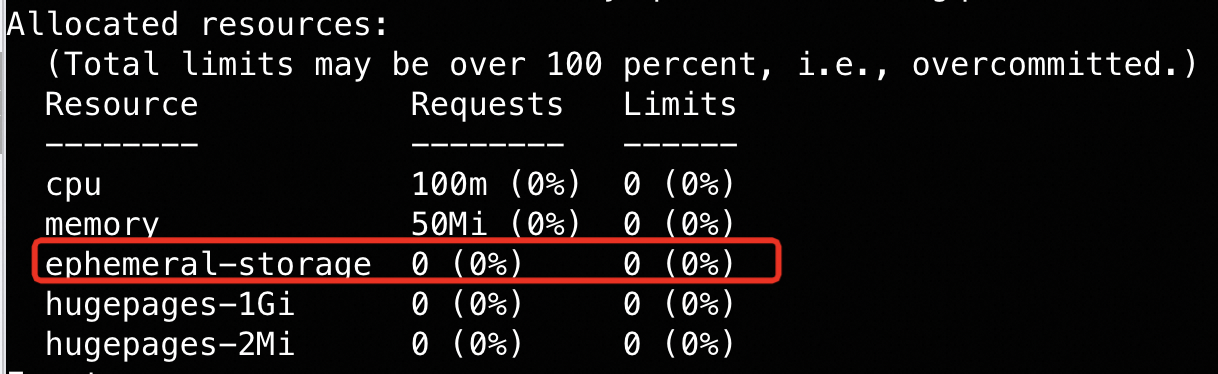
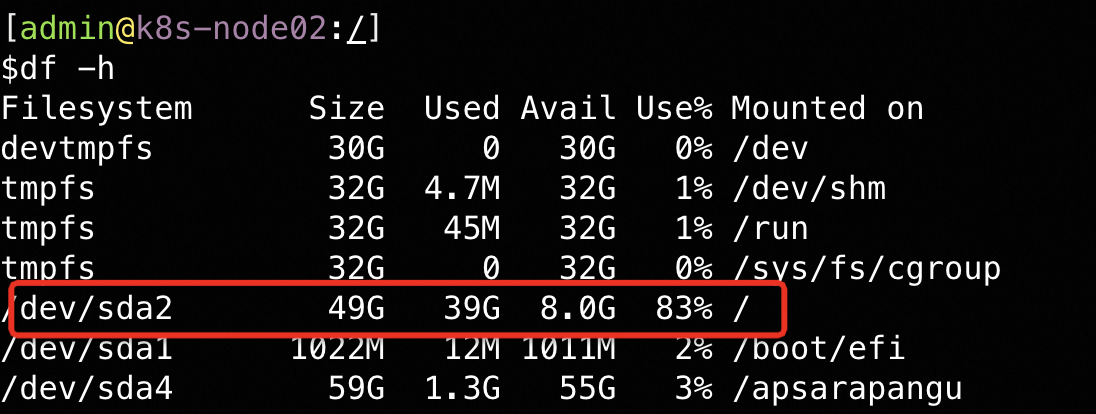
登录node查看
就是查看 / 这个根目录, 上边 ephemeral-storage 就是通过查看这个根目录上报的:
如何处理?
- 查看具体根目录下那个目录/文件 占用最多:
sudo du -h --max-depth=1 /- 发现基本都是
/var/lib/docker/overlay2这个目录下 占用了空间:
sudo du -h /var/lib/docker/overlay2 | sort -h -r | head -n 10
只能通过:
- 删除不用的容器
k delete pod xxx - 清理掉node上的缓存
docker image prune -a
docker volume prunePod Evicted
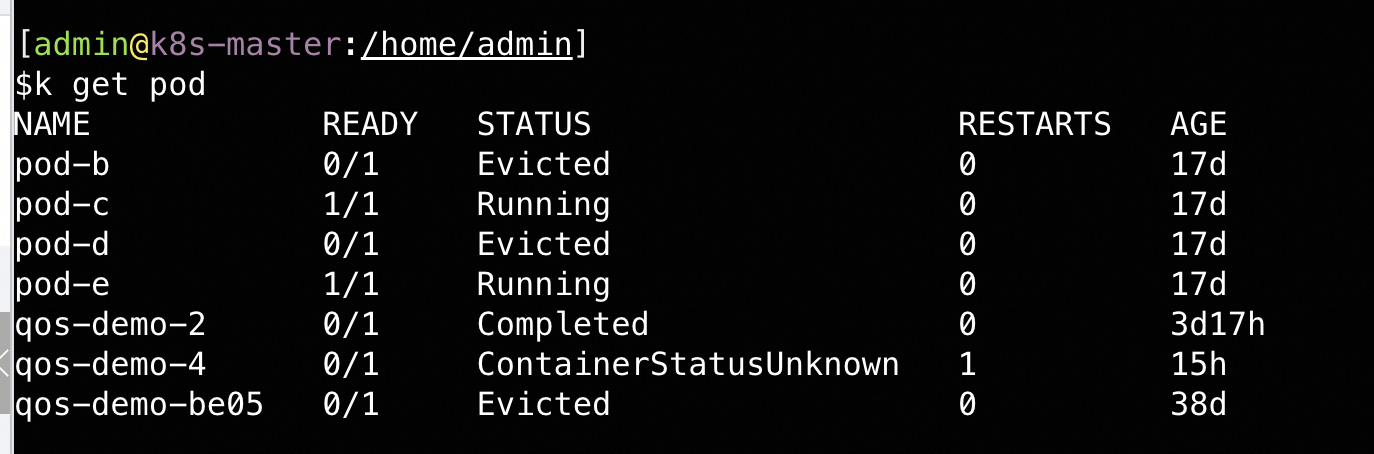
- 如何查询pod为啥会被evicted?
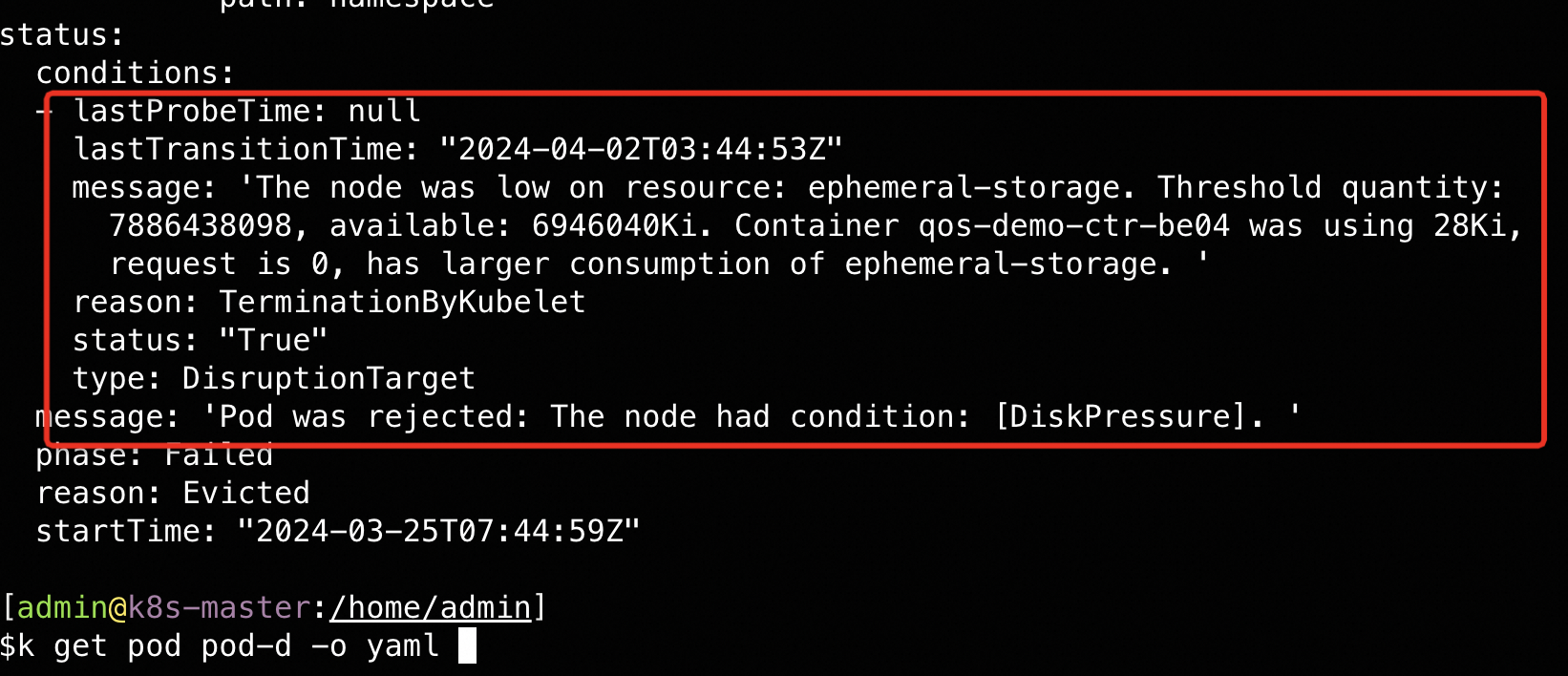
- 一般如何处理这种evicted的pod?
一般都查出原因之后, 直接删除Pod. 但k8s原生没有提供自动清理这些pod的机制.
在 Kubernetes 中,Pod 被驱逐(Evicted)后通常不会自动被删除,以便您能查看并调查问题。但是,如果你希望自动清理这些被驱逐(Evicted)的 Pod,你可以通过编写一个简单的脚本来定期检查并删除它们。然后,你可以将这个脚本作为一个 CronJob 在 Kubernetes 集群中定期运行,或者在集群的节点上使用系统 cron 来运行。
- 这种被evicted的pod, 在调度记账中, 会扣减资源么?
- 如果会扣减, 那么如何防止过多地占用资源? 但实际又没有使用.
- 如果不会扣减, 那么是否会存在Pod刚被evict出去, 就又有相同的pod调度上去, 从而又被evict. 死循环的问题?
- 答案是 不会扣减, 但如何防止重新被调度? —> Node会被自动打上 NoSchedule:DiskPressure这个标签, 从而防止被调度.
Nameserver limits exceeded